
Préambule
Aujourd’hui, j’aimerais vous parler d’un proof-of-concept que je viens tout récemment d’appliquer dans mon travail. Mais avant ça, j’aimerais raconter comment j’en suis venu à m’intéresser au sujet dont je m’apprête à vous parler.
J’ai toujours aimé le SQL. Ce langage à la fois simple et élégant permettant d’effectuer des requêtes au sein d’une base de données, comme si on lui parlait directement.
Quand j’étais à l’école, c’est peut-être la première fois qu’en informatique j’avais l’impression de parler une autre langue. Une base de données nous fournira toujours les informations que l’on veut, pour peu qu’on sache comment les lui demander.
Je suis alors devenu développeur, et je me suis rappelé que si j’ai appris à communiquer avec une base de données c’était surtout pour l’appliquer au sein même de mes programmes. Inclure des requêtes SQL dans un code source, donc.
Comme tout étudiant j’ai connu la joie d’écrire des SELECT * et INSERT INTO dans des chaînes de caractères concaténées à des valeurs que je passais dans des formulaires, et l’émerveillement de voir s’afficher les données de ma base dans mes pages web.
Comme beaucoup d’étudiants, j’ai mis mes premiers sites web en ligne pour les montrer fièrement à tout le monde.
Puis comme tous ceux qui ont fait la même chose que moi, j’ai découvert la joie de me faire poutrer ma base de données à grands coups d’injections SQL.
Comment ça, concaténer des strings SQL, c’est pas bien ?
J’ai alors découvert comment faire de la préparation de requêtes.
Nous nous sommes tous heurtés aux mêmes problèmes :
- C’est rébarbatif
- On peut facilement faire des erreurs
- La peur de laisser passer une injection est toujours présente
- Il faut faire le mapping avec nos objets avec attention
Pour ce dernier point, je parlerai “d’objet” dans le cas général et le sens philosophique du terme, bien que je m’apprête à illustrer la problématique avec le langage Go qui n’est pas orienté objet.
Je n’étais pas le seul à avoir remarqué cette nécessité de mapper des structures / classes avec des tables de bases de données, d’autres l’ont remarqué bien avant moi. Ce sont ces gens qui ont créé les ORM (Object-Relational Mapping), permettant de répondre à ce besoin.
Les avantages des ORM sont immenses :
- On manipule directement des objets
- On abstrait totalement la couche SQL, même plus besoin d’écrire du SQL
- Facilite grandement la sérialisation / déserialisation
- Opérations CRUD simplifiées
- La gestion des relations est simplifiée
- Compatibilité entre plusieurs bases de données (PostgreSQL, MySQL, …)
Il y a également des inconvénients incontournables :
- Perte de performance
- Contrôle plus limité
- Debugging parfois plus compliqué
- Apprentissage d’un DSL
Bien que ces inconvénients existent, les avantages sont bien trop évidents pour passer à côté. Le principe des ORM est largement adopté dans à peu près tous les langages de programmation.
J’adorais le langage SQL, mais je dois me faire une raison : écrire du SQL à notre époque est obsolète. Plus personne ne fait ça. C’est du moins ce que je pensais.
Cela fait des années que je parle avec mes bases de données via des ORM, et je m’y suis accommodé. Mais je dois vous avouer que je suis nostalgique de l’époque où je parlais la langue de mes bases de données.
Récemment au travail, nous avons été confrontés à certains problèmes liés à ce manque de contrôle qu’entraînent parfois les ORM, notamment lorsque nous devions changer le schéma de la base de données.
C’est alors qu’un collègue est venu nous présenter une technologie que je ne connaissais pas encore : sqlc.
sqlc et les ORMs
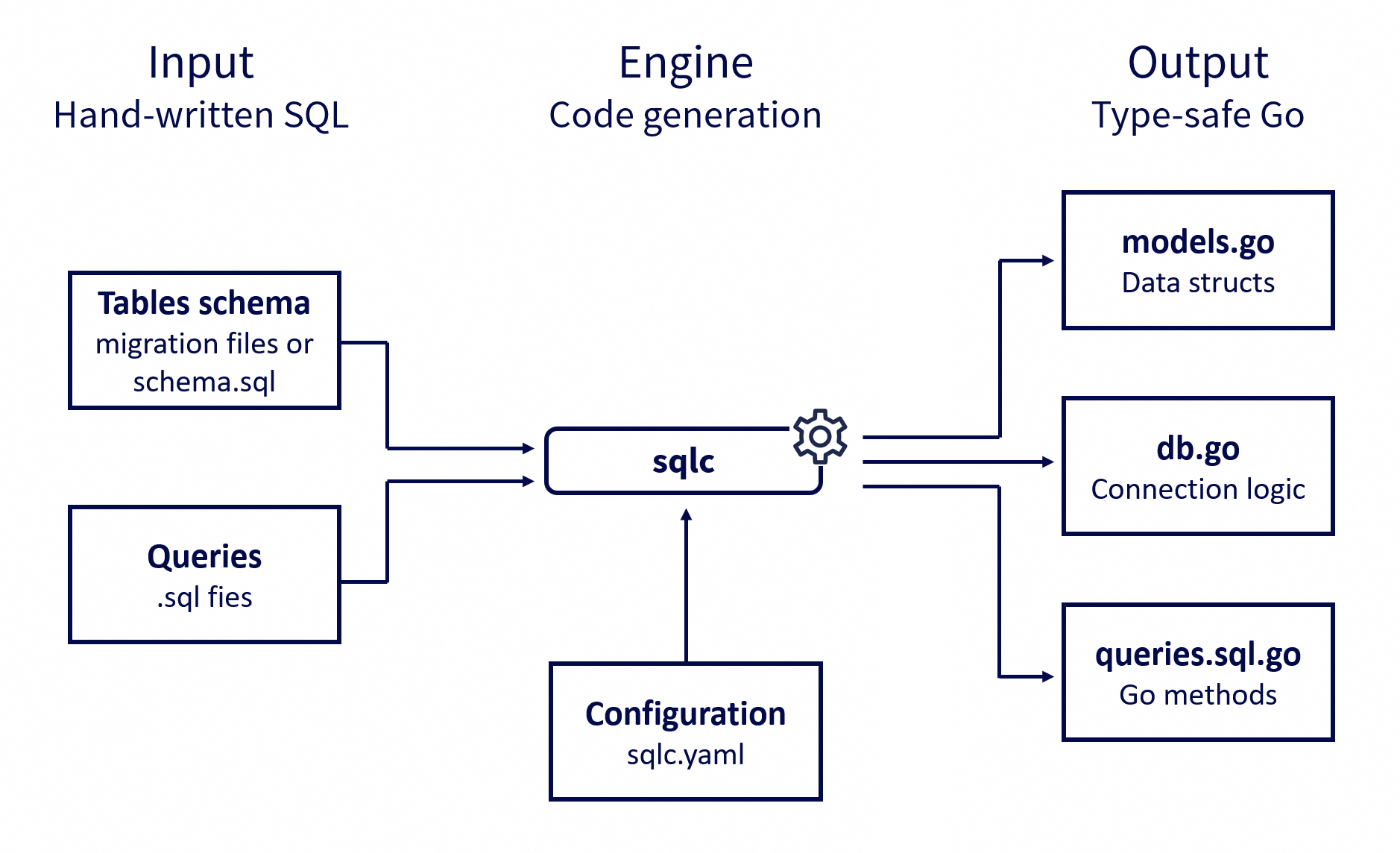
sqlc est un outil qui génère automatiquement du code à partir de requêtes SQL écrites manuellement.
Il a été créé pour combiner la sécurité et la performance du SQL brut avec la facilité d’utilisation d’un ORM, tout en évitant la surcharge de traitement et la perte de contrôle que peuvent introduire ces derniers.
Initialement écrit en Go pour du langage Go, sqlc supporte aujourd’hui plusieurs autres langages.
Ici, nous en parlerons essentiellement en Go. Pour bien situer sqlc dans l’écosystème actuel, nous utiliserons à titre comparatif l’ORM GORM (bien qu’il existe d’autres alternatives populaires comme Ent).
Prenons un schéma de base de données très simple :
|
|
À première vue ça ressemble un peu à un retour en arrière : on utilise de nouveau des requêtes préparées écrites directement dans notre code source.
Dans le cas des ORM, le SQL est totalement invisible.
Ajouter une ligne dans une base de données prend littéralement une ligne de code :
|
|
Cependant, comme dit plus haut, nous voulons nous affranchir des limitations des ORM. Si manipuler des bases de données avec un ORM est aisé avec des exemples triviaux, qu’en est-il lorsque nous voulons exécuter des requêtes complexes ?
Ce n’est pas forcément impossible, mais nous oblige parfois à faire des concessions (découpage des requêtes pour déléguer une partie des calculs au langage de programmation, création de vues, etc.)
Au final, les inconvénients induits par les requêtes préparées manuellement, n’y a-t-il pas un autre moyen de les gérer ?
sqlc prend le problème dans l’autre sens : pas de dépendance dans le code, mais un outil en local qui génère du code compatible librairie standard.
À noter que de la génération de code vers d’autres librairies est également possible, mais ici c’est le fait de ne pas avoir de dépendances autres que la librairie standard qui nous intéressera.
Le résultat :
- On écrit à nouveau du code SQL
- On obtient du code 100% compatible librairie standard prêt à l’emploi
Mais avant d’écrire le moindre SQL, sqlc a besoin de savoir quelques petites choses : quel moteur de base de données on utilise, où trouver nos requêtes et notre schéma, et où générer le code. Tout ça se définit dans un fichier de configuration, sqlc.yaml (ou sqlc.json, si vous préférez), placé à la racine du projet.
Voici celui que j’ai utilisé :
|
|
C’est assez simple : j’indique à sqlc que j’utilise PostgreSQL, que mes requêtes SQL se trouvent dans sqlc/database/*.sql, que le schéma de la base de données est défini par les scripts de migration dans sqlc/database/migrations, et que le code Go généré doit aller dans le package sqlc/database.
Une fois en place, une simple commande sqlc generate suffit pour générer le code.
Passons maintenant au SQL.
Il suffit juste d’ajouter un commentaire au-dessus des requêtes afin de spécifier le nom de la fonction désirée :
author.sql
|
|
author.sql.go (fichier généré)
|
|
C’est une autre façon d’appréhender le problème : fini d’écrire du boilerplate, plus à craindre de potentielles injections dues à des erreurs humaines.
Des avantages très proches de ceux fournis par les ORM en somme, mais avec un contrôle direct sur les requêtes et surtout sans surcoût à l’exécution. En effet, contrairement à certains ORM qui s’appuient fortement sur la réflexion au runtime, le code généré par sqlc s’exécute tel quel, sans perte de performances.
Vous pouvez trouver un exemple plus complet sur le sqlc Playground.
Écrire du SQL, c’est cool.
Vous noterez que le SELECT * a été transformé en SELECT id, email, bio dans le code généré.
En effet, sqlc remplace SELECT * par une liste explicite de colonnes pour garantir la stabilité du code généré, optimiser les performances et éviter les erreurs liées aux changements de schéma.
Vous remarquerez ensuite que la comparaison entre l’utilisation des fonctions fournies par un ORM et celle des fonctions générées par sqlc est assez similaire.
GORM
|
|
sqlc
|
|
Dans le cas de sqlc, on utilise une structure de type *Queries, qui est une encapsulation de DBTX, une interface qui définit un contrat pour exécuter les requêtes SQL. Tous deux sont générés par sqlc.
Libre à nous de les utiliser comme on veut. Pour ma part, j’ai choisi de rendre les fonctions générées internes (d’où le fait qu’elles commencent par une lowercase), afin de les encapsuler par des fonctions exportées du même nom que je définis comme méthode de *Queries.
Et c’est tout ! Tout aussi simple à utiliser qu’avant, mais avec bien des avantages.
D’ailleurs, des avantages, il y en a d’autres. J’aimerais justement attirer l’attention sur deux d’entre eux que j’apprécie beaucoup.
Premièrement, les modèles sont eux aussi générés par des scripts SQL.
Génération de modèles
Voici les modèles Go générés par mes scripts SQL :
|
|
Vous commencez à comprendre le concept de sqlc, ces modèles ont bien évidemment été écrits par des scripts SQL.
Voici donc un script SQL qui permettrait la génération de ces modèles :
|
|
Ça fonctionne, mais en entreprise les tables de nos bases de données sont rarement figées, elles évoluent. C’est pour cela que l’on trouvera en général plutôt des scripts de migration.
C’est là que ça devient intéressant : si sqlc est capable de générer nos modèles via du SQL, il peut du coup le faire via des scripts de migration directement.
Voici les scripts que j’ai réellement utilisés pour obtenir le même résultat :
v0001.sql
|
|
v0002.sql
|
|
v0003.sql
|
|
Chez nous, la gestion des bases de données est effectuée par une équipe dédiée. Ils ont leurs propres repos Git, et nous faisons des PR chez eux pour faire évoluer nos schémas.
Grâce à sqlc, nous pouvons maintenant ajouter directement ces repos via des Git submodules afin de faire en sorte que sqlc aille directement chercher les scripts de ces repos afin de générer nos modèles.
Avant, nous étions obligés de reproduire les modèles de données au sein de notre code, avec les erreurs humaines que ça implique.
Cette méthode permet d’obtenir un lien réel et fiable entre le code de nos microservices et celui des migrations de base de données.
L’équipe en charge des bases de données devient ainsi la réelle source de vérité.
À titre d’exemple, j’ai reproduit ce proof-of-concept à la maison : https://github.com/sebferrer/poc-sqlc ;
et j’ai stocké mes scripts de migration dans un repo dédié : https://github.com/sebferrer/poc-sqlc-db
Transactions
Un point important à savoir : sqlc ne génère pas de transactions automatiquement. Si on veut exécuter plusieurs requêtes au sein d’une même transaction, il faut le gérer soi-même.
Mais ce n’est pas bien compliqué, car sqlc fournit un mécanisme bien pratique pour ça. Le code généré inclut une méthode WithTx sur la structure *Queries, qui permet d’associer nos requêtes à une transaction existante :
|
|
L’idée est simple : on démarre une transaction via la librairie standard, puis on crée une nouvelle instance de *Queries liée à cette transaction grâce à WithTx. À partir de là, toutes les requêtes exécutées sur cette instance feront partie de la même transaction.
Voici un exemple concret : imaginons qu’on veuille créer un auteur et lui assigner un livre dans la foulée, le tout au sein d’une même transaction.
|
|
Si l’une des opérations échoue, le defer tx.Rollback() se charge de tout annuler. Si tout se passe bien, tx.Commit() commit la transaction.
Pour finir, si vous voulez en savoir un peu plus, je vous laisse sur quelques dernières notes comprenant certaines subtilités bonnes à connaître que j’ai remarquées sur sqlc.
Quelques subtilités
Structures de paramètres
sqlc génère des structures Go pour encapsuler les paramètres des requêtes SQL, mais uniquement lorsqu’il y a plus d’un paramètre. Si la requête SQL n’a qu’un seul paramètre, sqlc n’utilise pas de structure et passe directement la valeur correspondante à la fonction.
On a pu remarquer dans l’exemple plus haut qu’une structure a été générée pour pouvoir passer les paramètres nécessaires, afin de pouvoir la passer à la fonction elle aussi générée :
|
|
Ça aurait été la même chose pour la requête SELECT si elle avait eu besoin de plus d’un seul paramètre.
En revanche, si un seul paramètre est nécessaire à la requête, sqlc ne s’embêtera pas à créer une structure pour rien :
|
|
|
|
Structure de retour
On peut également se demander, comment sqlc gère le type de retour pour renvoyer les données sélectionnées ? C’est assez simple.
Si le SELECT comporte toutes les colonnes de la table, comme un SELECT *, il utilisera directement le type généré pour définir le modèle de données.
|
|
|
|
Sinon, il génère une structure intermédiaire, nous laissant le libre choix de comment la gérer.
|
|
|
|
Embedding avec sqlc.embed
Quand on écrit des requêtes avec des JOINs, la structure résultante générée contient habituellement une liste à plat de toutes les colonnes sélectionnées. Ça peut vite devenir pénible à manipuler.
Par exemple, la requête suivante récupère des livres avec leurs auteurs :
|
|
sqlc génèrerait une structure à plat comme celle-ci :
|
|
Avec sqlc.embed, on peut indiquer à sqlc de réutiliser les structures de modèles existantes :
|
|
La structure générée sera alors bien plus propre :
|
|
Le code généré reste ainsi bien organisé, et on n’a pas besoin d’extraire manuellement chaque champ d’une ligne à plat.
Paramètres nommés avec sqlc.arg
sqlc essaie de générer des noms pertinents pour les paramètres positionnels, mais parfois il manque de contexte. Par exemple :
|
|
|
|
Pas très lisible. Avec sqlc.arg, on peut nommer explicitement les paramètres :
|
|
|
|
Si la syntaxe vous paraît trop verbeuse, vous pouvez aussi utiliser le raccourci @ :
|
|
Note : le raccourci
@n’est pas supporté avec MySQL.
Paramètres nullables avec sqlc.narg
sqlc infère la nullabilité des paramètres, et généralement ça fait ce qu’on veut. Toutefois, si on veut nous-même forcer la nullabilité d’un paramètre qui n’aurait pas été inféré comme tel (parce que la colonne est NOT NULL), sqlc propose également sqlc.narg (nullable arg), qui permet justement de le faire.
C’est particulièrement utile pour les mises à jour partielles, où l’on veut qu’un champ reste inchangé si aucune nouvelle valeur n’est fournie.
Voici un exemple qui permet de mettre à jour l’email, la bio d’un auteur, ou les deux :
|
|
|
|
Ici, sans sqlc.narg, le paramètre email aurait été généré en tant que string (non-nullable) puisque la colonne est NOT NULL. En utilisant sqlc.narg, on le force à être sql.NullString, ce qui nous permet de passer NULL pour signifier « ne change pas ce champ ».
Le revers de la médaille : les requêtes dynamiques
Tout n’est pas rose pour autant. Là où un ORM comme GORM brille par sa capacité à construire des requêtes dynamiques (ajouter un Where() seulement si une variable est définie par exemple), sqlc montre ses limites. Comme tout est figé à la compilation, gérer une barre de recherche avec dix filtres optionnels devient vite un casse-tête.
On pourrait être tenté de ruser avec du SQL un peu « gras » du type WHERE (column = $1 OR $1 IS NULL), mais soyons honnêtes : c’est rarement une solution envisageable sur des projets sérieux. C’est verbeux, difficile à maintenir et souvent catastrophique pour les performances dès que la table prend du volume.
Dans ce genre de scénario, il faut savoir rester pragmatique : la meilleure option selon moi est de renoncer à sqlc pour ces cas précis et utiliser un Query Builder (comme Squirrel) ou du SQL brut, uniquement pour ces requêtes complexes.
C’est le prix à payer pour la sécurité du typage : on gagne en rigueur sur 95 % du projet, mais on accepte de reprendre la main manuellement sur les 5 % restants.
Autres subtilités en vrac
- Comme vous avez pu le voir, les champs NULL en SQL sont représentés avec
sql.NullXxxen Go : ça permet de gérer les valeursNULLsans erreur d’exécution (type-safe). - Les requêtes
INSERT ... RETURNINGpermettent d’obtenir l’ID d’un nouvel enregistrement directement : sqlc les traduit enQueryRowContext(au lieu d’un simpleExecContext) et utiliseScanpour récupérer la valeur retournée.
À noter également que sqlc ne propose pas que de la génération de code utilisant la librairie standard database/sql mais propose également pgx/v4 et pgx/v5.
Bonus : faire du Mock
J’aimerais parler d’un autre avantage qui m’a marqué. Le fait de générer son code via sqlc simplifie grandement le mock, et ce pour une bonne raison : c’est nous qui avons écrit le script SQL, donc nous savons exactement à quoi nous attendre.
Cela peut paraître anodin, mais rappelez-vous que si via un ORM nous n’avons aucun contrôle sur le code SQL qui est réellement généré derrière, ça peut rendre les mocks particulièrement fastidieux à écrire.
Je veux mocker la requête SELECT générée derrière mon Get, je dois m’attendre à quoi du coup ? Quelle est la requête exacte que je dois intercepter ?
Prenons l’exemple de GORM :
|
|
Ça fonctionne, c’est cool. Mais il a fallu que je comprenne un minimum comment fonctionne GORM pour savoir que c’est spécifiquement cette requête qu’on doit attendre si je veux faire un mock de ma fonction Get.
Est-ce que mon ORM génère les mots-clés en lowercase ou uppercase ? Est-ce qu’il utilise des quotes, double-quotes ? Est-ce qu’il génère systématiquement le nom de la table devant la colonne associée ? Etc…
Répondre à ces questions implique de bien lire la documentation, voire de carrément aller dans le code source de l’ORM. On peut également se servir des messages d’erreurs de la librairie de mock SQL qu’on utilise, mais il faut reconnaître que ça demande du bricolage.
Et ce, pour chacune des requêtes SQL impliquées dans vos mocks.
Une fois passé à sqlc, le mock ressemblera à ça :
|
|
C’est-à-dire exactement la requête que j’ai moi-même écrite à la base (ou presque, cf. l’exemple du SELECT *, mais la requête générée est directement accessible).
Quand on doit mocker toute une batterie de requêtes SQL pour nos tests unitaires, j’ai découvert à quel point c’est plus pratique de n’avoir qu’un simple copié-collé de mes requêtes à faire.
Selon moi, une solution comme sqlc donne une réelle valeur ajoutée à l’utilisation de librairies de mock SQL.
Conclusion
Je pense avoir à peu près fait le tour de ce que je voulais vous présenter.
J’espère avoir pu transmettre la raison pour laquelle je me suis intéressé à cette approche un peu différente de ce que beaucoup d’entre nous utilisent couramment.
En conclusion, les ORM comme GORM offrent une abstraction robuste, facilitent les migrations et proposent une interface CRUD intuitive, mais nécessitent un investissement en apprentissage (bien que léger) et peuvent introduire une surcharge de performance, notamment avec de grandes bases de données et des opérations complexes.
Le SQL pur, de son côté, offre plus de contrôle sur les requêtes et peut être plus efficace pour les grandes bases de données, mais il demande une bonne maîtrise du SQL, implique une implémentation plus longue dans le code Go et devient vite complexe à gérer dès que l’on a besoin de requêtes aux paramètres très dynamiques.
Je dirais donc : si la simplicité et la rapidité de développement sont prioritaires, un ORM comme GORM reste une excellente option. Si l’optimisation, le contrôle précis des requêtes et la sécurité du typage sont essentiels, alors je préconiserais l’approche sqlc, tout en gardant le SQL pur en réserve pour les cas les plus complexes.
L’idée n’est pas de dire qu’une façon de faire est mieux qu’une autre.
J’adore les ORM et je continue d’en utiliser dans beaucoup de mes projets, mais j’avais envie de vous faire découvrir ce principe qui a été l’un de mes coups de coeur de l’année.
Enfin, sqlc s’affirme de plus en plus comme un outil pérenne : initialement très centré sur l’écosystème Go, il s’ouvre désormais à d’autres horizons avec le support officiel (actuellement en beta) de langages comme Python, Kotlin, ou TypeScript via un système de plugins.
Liens utiles
sqlc
- https://sqlc.dev/
- https://play.sqlc.dev/
- https://docs.sqlc.dev/en/stable/index.html
- https://github.com/sqlc-dev/sqlc
GORM
Comparaison / Benchmark
- https://blog.jetbrains.com/go/2023/04/27/comparing-db-packages/
- https://medium.com/hyperskill/using-gorm-versus-plain-sql-to-interact-with-databases-in-go-39728974edc8
- https://www.codementor.io/@patriciotula/building-a-todos-app-in-go-comparing-database-sql-and-gorm-2n921bkfyk
Mon proof-of-concept
Un Grand merci à Gab qui m’a fait découvrir cette techno et qui m’a donné envie de m’y intéresser !