
Un jour, un collègue m’a dit :
Parce que c’est le cas.
Cette phrase m’a fait rire, mais je l’ai trouvée tellement vraie que j’ai tout de suite su que je la citerais dans ma conférence qui traite de gestion d’incidents.
Ce blog post est complémentaire à mon précédent Run ! qui traite du sujet du RUN, afin d’y apporter quelques conseils de développeur complémentaires.
Tout comme dans le précédent post, les exemples sont basés sur le langage Go.
Logs
La première chose dont j’ai envie de parler sont les logs.
Définition d’AWS : Un fichier de log est un fichier généré par un logiciel qui contient des informations sur les opérations, les activités et les patterns d’utilisation d’une application, d’un serveur ou d’un système informatique.
Un log agit un peu comme une trace de vie numérique, permettant aux administrateurs et développeurs d’analyser le comportement du programme, de diagnostiquer les anomalies et d’assurer le suivi des opérations pour une meilleure maintenance et optimisation.
Les logs sont un peu les empreintes laissées par votre programme. Sans eux, pas d’enquête.
Il existe plusieurs niveaux de log, les principaux étant :
- INFO : Indique qu’un événement s’est produit, mais qu’il n’affecte pas la fonctionnalité du système.
- WARN : Signifie qu’un événement inattendu s’est produit, pouvant perturber ou retarder d’autres processus.
- ERROR : Indique qu’au moins un composant du système est inopérant et interfère avec le fonctionnement d’autres fonctionnalités.
- FATAL : Indique qu’au moins un composant du système est inopérant, provoquant une erreur fatale au sein du système global.
Utilisons logrus en Go pour illustrer.
Exemple typique de logs qu’on peut laisser dans un programme :
|
|
Ainsi, on verra passer des logs d’erreur ou d’information en fonction de si l’opération s’est bien passée ou non.
Le souci ici, c’est qu’on verra passer des messages comme :
|
|
Ça paraît clair, mais maintenant imaginez-vous devoir troubleshooter une erreur concernant un utilisateur, vous avez besoin de trouver les logs d’erreur et d’infos concernant un user ID en particulier.
On pourra certainement récupérer la donnée, mais sur des messages très verbeux et de manière absolument pas optimisée.
Ça fonctionne, mais comme je l’ai mentionné dans mon blog post Run !, un message de log se doit d’être le plus concis possible. Il y a les champs pour les informations complémentaires.
|
|
Ainsi, si par exemple vous voulez regarder les logs concernant un succès de l’opération, vous pourrez les retrouver via une simple requête.
Exemple via une requête Lucene dans Elasticsearch :
message:"user processing success" AND user_id:42
Cette logique est à appliquer quel que soit le niveau de log.
Ceci étant dit, il y a un point primmordial concernant les logs : éviter à tout prix le manque de données.
Loggez tout ce qui doit l’être, avec les champs pertinents.
Il n’y a pas pire que de se rendre compte seulement lors du troublehsooting qu’il nous manque des informations.
“Ah mince j’aurais dû logger cette information là”, “J’aurais dû mettre un champ pour cet ID”.
Une insuffisance d’informations, c’est un tour de manège gratuit pour redéployer un patch contenant l’information dont vous avez besoin pour diagnostiquer.
On commence vraiment à logger différemment quand on commence à faire soi-même du troubleshooting et qu’on réalise les besoins réels.
Il faut anticiper au maximum.
À noter cependant : même s’il vaut mieux trop d’informations que pas assez, il est important de différencier ce qui est pertinent à logger de ce qui ne l’est pas afin de limiter le bruit (ainsi que l’espace de stockage utilisé).
Voici quelques informations que je considère comme étant pertinentes à logger en général :
- Request ID
- URL Path -> Les paths des endpoints qui sont appelés par votre programme
- HTTP Method
- HTTP Error Code
- User IDs (ou ID des différents éléments que vous manipulez)
- Stack trace
- App Version
- Operation -> Ce qu’on était en train de faire au moment du log
Monitoring
Après avoir exploré l’importance des logs pour tracer les événements et diagnostiquer les incidents, il est essentiel d’aborder un autre pilier de l’observabilité : le monitoring.
Le monitoring permet d’anticiper les problèmes en surveillant en temps réel diverses métriques telles que les performances, la disponibilité des systèmes, ou l’état global de fonctionnement de votre système.
Parmi les métriques essentielles, on retrouve la latence des requêtes, la charge CPU, l’utilisation de la mémoire, le taux d’erreurs, la disponibilité (uptime), les délais de réponse des services, etc…
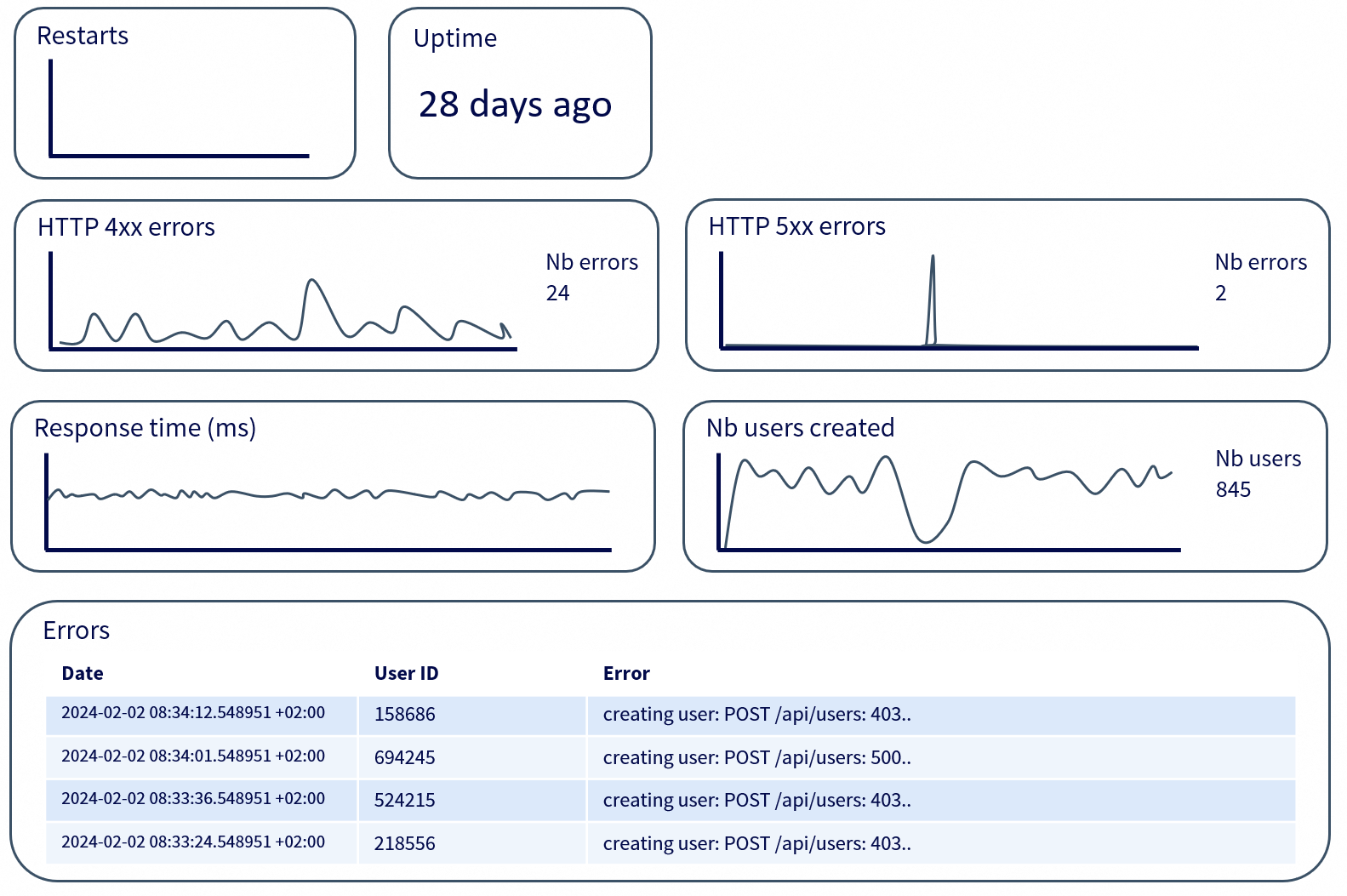
Ceci est une illustration classique d’à quoi peut ressembler un dashboard de monitoring d’un microservice, mais on peut faire des dashboards pour une infinité d’autres besoins.
Si ça vous intéresse d’avoir d’autres exemples plus concrets, n’hésitez pas à vous balader dans les dashboards du Play Grafana.
Erreurs
La gestion des erreurs primmordiale un programme, notamment lorsqu’il s’agit de diagnostiquer et comprendre les problèmes rencontrés.
En Go, les fonctions peuvent retourner plusieurs valeurs, et cela est couramment utilisé pour la gestion des erreurs.
Généralement, toute fonction susceptible d’échouer retournera deux valeurs :
- La valeur attendue (si l’opération réussit).
- Une erreur (
error) en deuxième valeur (si un problème survient).
Exemple :
|
|
Une erreur est avant tout une information précieuse, et bien la manipuler permet non seulement de remonter la cause d’un problème, mais aussi d’améliorer la lisibilité et la maintenabilité du code.
Il existe plusieurs manières de gérer les erreurs en Go, les principales étant :
- Retourner l’erreur brute : Simple mais insuffisant pour un bon contexte.
- Wrapping d’erreur : Fournit du contexte supplémentaire sur la cause de l’erreur.
- Ajout de logs : Permet d’exploiter l’erreur en la journalisant correctement.
Un problème fréquent dans la gestion des erreurs est le manque de contexte. Lorsqu’une erreur est retournée telle quelle, elle peut devenir difficile à exploiter en cas de debugging. On sait qu’une erreur s’est produite, mais sans indication précise sur son origine.
Prenons un cas où l’on charge un utilisateur depuis une base de données :
|
|
Si cette fonction échoue, l’appelant recevra l’erreur brute de la base de données. Le problème est que cette erreur peut être générique, sans précision sur l’opération en cours.
Pour améliorer cela, on peut enrichir l’erreur avec du contexte en utilisant fmt.Errorf et %w :
|
|
Désormais, l’erreur propagée inclura l’identifiant de l’utilisateur ainsi que la cause sous-jacente.
Là où la gestion des erreurs devient vraiment utile, c’est lorsqu’il faut les différencier. Toutes les erreurs ne doivent pas être traitées de la même façon. Certaines sont fatales, d’autres doivent simplement être signalées.
Go permet de tester le type d’une erreur avec errors.Is et errors.As, ce qui évite d’avoir à comparer des chaînes de caractères.
|
|
L’erreur ErrUserNotFound est ainsi facilement identifiable, ce qui permet à l’appelant de réagir en conséquence sans avoir à parser un message d’erreur textuel.
Lorsqu’une fonction appelle plusieurs services ou effectue des opérations en cascade, chaîner les erreurs permet de garder une trace complète du problème. C’est ce que permet le wrapping avec %w.
Un bon système de gestion d’erreurs n’est pas seulement utile pour afficher des messages, il doit faciliter le troubleshooting en fournissant un maximum d’informations sans bruit inutile.
Une erreur vide de contexte est aussi inefficace qu’un log mal structuré. Si une erreur doit être propagée, elle doit l’être avec toutes les informations nécessaires pour comprendre d’où elle vient et pourquoi elle est survenue.
Alertes
L’utilité d’une gestion des erreurs et du monitoring est remise en question si personne n’est informé quand un problème survient.
C’est là qu’interviennent les alertes, qui permettent de détecter et signaler automatiquement les anomalies critiques.
Cet article traite principalement des bonnes pratiques de dev concernant la gestion d’incidents, et c’est justement ces alertes qui entraînent la création d’incidents.
Une alerte doit être réactive et pertinente. Réactive, car elle doit prévenir rapidement les bonnes personnes, et pertinente, pour éviter le bruit et la fatigue liée aux fausses alertes.
Il est inutile de recevoir une notification pour chaque petite anomalie, mais ignorer une augmentation soudaine du taux d’erreurs HTTP 500 serait une erreur critique.
Les alertes peuvent être déclenchées à partir de plusieurs sources :
- Les logs : Surveiller un volume anormalement élevé de logs
ERRORouFATAL. - Les métriques : Détection d’une latence excessive, d’une montée en charge CPU, ou d’une saturation de mémoire.
- Erreurs Application-Level : Capturez les erreurs explicitement déclenchées dans le code, telles que
fmt.Errorf(...),throw new Error(...)ouraise Exception(...). Celles-ci peuvent indiquer des défaillances de la logique métier, des défaillances d’assertion ou d’autres conditions critiques définies par les développeurs.
Prenons un exemple avec des règles Prometheus et Alertmanager pour détecter une hausse des erreurs 500 :
|
|
Ici, si plus de 5 % des requêtes échouent avec une erreur 500 sur une période de 5 minutes, une alerte est déclenchée après 2 minutes de persistance du problème.
Mais une alerte en soi ne sert à rien si elle n’atteint pas les bonnes personnes. Un bon système d’alerting doit être intégré à des outils comme :
- Opsgenie, PagerDuty pour réveiller quelqu’un en cas d’urgence.
- Slack, Mattermost, Microsoft Teams ou Webex pour notifier l’équipe.
Le niveau d’urgence d’une alerte doit être défini en fonction de son impact.
Un simple pic de latence sur une requête peu critique ne doit pas générer une alerte critique, alors qu’une perte de connexion à une base de données doit immédiatement déclencher une intervention.
C’est ce niveau d’urgence qui définit la priorité de l’incident qui en découlera.
Enfin, une alerte bien configurée ne doit pas simplement être un signal d’alarme : elle doit permettre d’identifier la cause du problème rapidement.
Associer les alertes aux logs, aux métriques et au tracing est essentiel pour éviter de passer des heures à chercher l’origine d’un incident.
Une erreur critique qui passe inaperçue peut coûter des milliers d’euros en downtime.
À l’inverse, un système qui alerte trop souvent sans raison perdra toute crédibilité et les alertes finiront par être ignorées.
Trouver le bon équilibre est un travail d’itération et d’ajustement permanent.
Architecture de code
J’aimerais terminer sur un aspect que je trouve important : plus vous avez un nombre important de projets qui tournent en production, plus appliquer toutes ces méthodes vous seront difficile si vous n’appliquez pas une certaine rigueur dans votre architecture de code.
J’aurais trois conseils à vous donner :
Concevez et utilisez un archetype
Si vous savez que votre équipe va être amenée à développer une certaine quantité de microservices ayant des objectifs plus ou moins similaires, ayez une base solide de code que vous pouvez réutiliser.
C’est cette même base qui vous permettra pas défaut, lors de la création d’un nouveau projet, d’avoir des branchements déjà établis avec votre CI/CD, votre artifact repository, vos gateways, …
Concevez et utiliser une collection de packages communs solide
À chaque fois que vous savez que vous allez avoir besoin d’une évolution qui szra utile pour l’ensemble de vos projets, développez-les au sein d’une collection de packages communs qui pourront être utilisés en tant que dépendances.
Que ça soit pour améliorer votre gestion de logging, alerting, profiling, requêtes HTTP, gestion d’erreurs, metrics et j’en passe.
Utilisez un linter
Le sujet des linters est vaste, et je ne vais pas m’y attarder ici.
Cependant, leur utilisation est indispensable pour garantir un code plus propre, plus cohérent et conforme aux bonnes pratiques.
Un linter permet de détecter automatiquement des erreurs potentielles, d’appliquer des conventions de style et d’éviter certaines mauvaises pratiques avant même l’exécution du programme.
Quelques exemples disponibles dans golangci-lint :
- govet : Détecte des erreurs potentielles (mauvaises utilisations de variables, erreurs logiques, etc…).
- revive : Analyse le style et les conventions du code pour le rendre plus propre et maintenable.
- errcheck : Vérifie que toutes les erreurs retournées par les fonctions sont bien traitées.
- staticcheck : Détecte des erreurs courantes, du code inutilisé et des pratiques obsolètes.
- gocyclo : Mesure la complexité cyclomatique des fonctions pour encourager un code plus simple.
Il y a certainement plein d’autres bonnes pratiques de développeur à connaître afin de produire le code le plus résilient possible, j’ai cité ici celles qui m’ont parues les plus essentielles.
À bientôt !
Sources
- https://preslav.me/2023/04/14/golang-error-handling-is-a-form-of-storytelling/
- https://www.crowdstrike.com/en-us/cybersecurity-101/next-gen-siem/logging-levels/
- https://aws.amazon.com/what-is/log-files/
- https://play.grafana.org/
- https://prometheus.io/docs/prometheus/latest/configuration/alerting_rules/
- https://betterstack.com/community/guides/logging/logging-best-practices/
- https://www.dataset.com/blog/the-10-commandments-of-logging/
- https://www.digitalocean.com/community/tutorials/handling-errors-in-go
- https://www.jetbrains.com/guide/go/tutorials/handle_errors_in_go/best_practices/
- https://www.ibm.com/think/topics/application-monitoring-best-practices
- https://www.keyprod.com/en/knowledge/production-monitoring