
Préambule
J’aimerais aujourd’hui parler d’une expérience professionnelle qui me tient à cœur.
Il y a tout juste un an, cela faisait déjà 12 ans que je pratiquais le métier d’ingénieur logiciel.
J’ai commencé en tant que développeur web. Je suis ensuite devenu spécialiste en deep learning, puis je me suis dirigé vers la cybersécurité pour travailler sur une IAM.
Bien que toutes différentes, ces expériences professionnelles ont toutes eu un point commun : je n’avais presque jamais touché à de la prod de ma vie.
Lors de mon expérience web, dès que j’avais push mon dernier commit, le code n’était même plus entre mes mains.
Mon expérience en IA s’est déroulée dans une équipe de proof-of-concept au sein d’un pôle d’innovation.
Lors de mon expérience en IAM, je mettais mes tickets Jira en “Done” quand j’avais push mon dernier commit, puis pareil : ce n’était plus entre mes mains.
Aussi, je n’ai toujours travaillé que sur un seul projet à la fois. Ou presque, mais vous avez l’idée.
C’est alors que je postule dans une équipe qui s’occupe du SI (système d’information) interne de l’entreprise. Je découvre qu’ils développent et opèrent sur une cinquantaine de microservices et middlewares en tous genres.
Je suis pris dans l’équipe, je découvre un peu plus en détail ce qu’ils font, et mon chef m’annonce alors deux objectifs annuels :
- Je dois être capable de faire du RUN dans 3 mois.
- Je dois intégrer la rotation d’astreinte nuit / week-ends 2 mois plus tard.
Je rentrerai un peu plus en détail sur ces deux principes juste après, mais je veux mettre l’accent sur le fait que, de par mon background, il m’était évident que j’étais incapable de réaliser ces objectifs.
Ma pensée fut : “C’est fou, mon nouveau chef a plus confiance en moi que moi-même”.
Au final, j’ai accompli ces objectifs sans aucun problème, malgré une appréhension certaine.
Comment ?
Les incidents sonnent dans tous les sens, la plupart du temps je n’avais encore jamais touché au microservice qui a déclenché l’alerte. Alors, comment ai-je pu m’en sortir sans trop de problèmes ?
C’est à cette question que j’aimerais répondre. J’aimerais vous raconter à quoi ressemble cette équipe, quelle est l’organisation et quels sont les outils qu’ils ont mis en place pour qu’un nouvel arrivant s’intègre aussi rapidement dans ce métier.
Je vais vous raconter quelles sont, selon moi, les ficelles essentielles du RUN.
Note : Je me focaliserai dans cet article sur le RUN, qui se passe de jour, et passerai beaucoup moins de temps sur l’astreinte qui se passe la nuit ou le week-end.
Bien que nous parlions d’incidents dans les deux cas, cela reste deux sujets différents.
Mes premiers incidents
Le RUN désigne l’ensemble des activités liées à l’exploitation, à la supervision et à la maintenance des systèmes en production. Il s’oppose au BUILD, qui regroupe les activités de développement, d’intégration, de test et de déploiement, réalisées à partir d’une phase de conception préalable.
On y retrouve plusieurs aspects : supervision et réaction aux incidents en temps réel, gestion des correctifs et patches de sécurité, gestion des SLA et suivi des KPIs de disponibilité…
La définition du RUN peut varier, mais l’idée à retenir selon moi est que le RUN s’inscrit surtout dans le présent : comment cela fonctionne, qu’est-ce qui est en train de se passer, comment corriger / améliorer.
Dans le cas de mon équipe, on parle surtout de gestion d’incidents, même si cela peut varier.
Dans un écosystème où cohabitent de nombreux microservices, les incidents peuvent survenir à tout moment. Les causes peuvent être nombreuses :
- Un cas non couvert dans le code source.
- Un service appelé qui ne répond plus.
- Un problème sur l’infrastructure.
- Une latence réseau.
- Une régression.
- Etc.
Et à peu près une infinité d’autres raisons, mais cela vous donne une idée.
Par chance, j’ai intégré l’équipe pile lors d’un nouveau besoin, j’ai alors pu développer un nouveau microservice en partant de zéro.
Ayant développé une grande partie du code de celui-ci et ayant la totalité du code en tête, il m’était alors relativement facile, une fois en production, de comprendre ce qu’il se passait en cas d’incident.
Je ne dis pas que trouver la solution à un problème qui survient sur un projet que l’on maîtrise est toujours aisé, mais au moins on sait à peu près dans quoi on met les pieds.
C’est alors que je me suis fait la réflexion suivante :
S’il est relativement aisé en cas d’incident de se forger une intuition sur un problème concernant un sujet maîtrisé, cela le devient beaucoup moins sur un sujet qui nous est inconnu.
Lors de ma première semaine de RUN, je n’étais pas serein. Mon téléphone sonne, je regarde l’alerte, et le nom du microservice me dit vaguement quelque chose.
Un message d’alerte du genre [user-sync-service] creating user: POST /api/users: 403....
Je ne connais pas ce projet. La première chose que j’ai immédiatement à ma disposition, c’est un préfixe contenant le nom du service et le début d’un message d’erreur. Vous avez remarqué qu’en assez peu de caractères, nous avons déjà pas mal d’informations ?
C’est là tout l’intérêt de bien formater ses messages de logs et d’erreurs dans son code.
Une bonne pratique consiste à répartir son message d’alerte en trois parties :
- Le préfixe contenant le nom du service impacté.
- Un message très court décrivant l’opération concernée.
- Le message d’erreur qui a été wrappé.
En un coup d’œil, j’ai déjà compris qu’il s’agit d’un microservice dont le but est de synchroniser des utilisateurs d’un endroit à un autre. J’ai compris qu’en essayant de créer un utilisateur vers la destination via un endpoint POST, une erreur 403 est survenue. Il s’agit donc potentiellement d’un problème d’autorisation.
Je suis loin d’être capable de troubleshooter le problème, mais j’ai déjà une piste pour orienter mes recherches.
Pour information, la synchronisation (ou l’interconnexion) consiste à transmettre de l’information d’un point à un autre. Généralement entre deux outils qui ne se connaissent pas et n’ont pas été spécialement conçus pour communiquer entre eux, mais qui disposent chacun d’une API REST qui propose des opérations CRUD.
L’idée est de dire : “Je prends des données d’une application, et je les envoie vers une autre application, en tenant compte de son format de données”. C’est globalement l’idée.
Autre exemple : [doc-sync-service] get document: unexpectedly empty result.
Visiblement encore une synchronisation. Mais cette fois-ci, il semblerait que le problème soit survenu au moment où on a essayé de récupérer un document à la source.
J’en profite pour mettre l’accent sur l’importance de bien rédiger ses messages d’erreurs. J’aime beaucoup cette vision proposée par cet article, que nous avons adopté : https://preslav.me/2023/04/14/golang-error-handling-is-a-form-of-storytelling/
Évidemment, je vais rapidement être amené à connaître tous les projets de mon équipe. Le but n’est pas de troubleshooter les yeux fermés toute ma vie, mais je préfère garder à l’esprit deux choses :
- Sur un périmètre dense, personne n’aura le même niveau de connaissance sur tous les projets.
- De nouvelles personnes pourront toujours rejoindre l’équipe.
En conclusion : ne jamais se reposer sur l’expérience de l’équipe en se disant que tout le monde connaît bien les projets, et toujours être le plus clair et concis possible dans sa gestion d’erreurs.
Le déroulement d’une semaine de RUN
Je commence à avoir un aperçu de ce à quoi peuvent ressembler les incidents, il est maintenant temps de commencer ma première semaine de RUN.
Je pense qu’il existe une multitude de façons de gérer le RUN. À défaut d’être exhaustif, je me contenterai de vous partager notre méthode et ce que j’ai appris.
Pour commencer, nous fonctionnons par semaines de RUN. C’est un procédé classique, bien que pas systématique selon les équipes. Cela signifie qu’on tourne à tour de rôle dans l’équipe pour prendre la semaine.
Être responsable du RUN implique d’être responsable du direct. Le direct avant tout. Cela implique plusieurs choses :
- Réaliser le morning check tous les matins.
- Prendre tous les incidents qui tombent en temps réel.
- Surveiller les tickets d’incident en cours.
- Être le point de contact de l’équipe concernant les sujets urgents.
Détaillons ces points.
Morning check
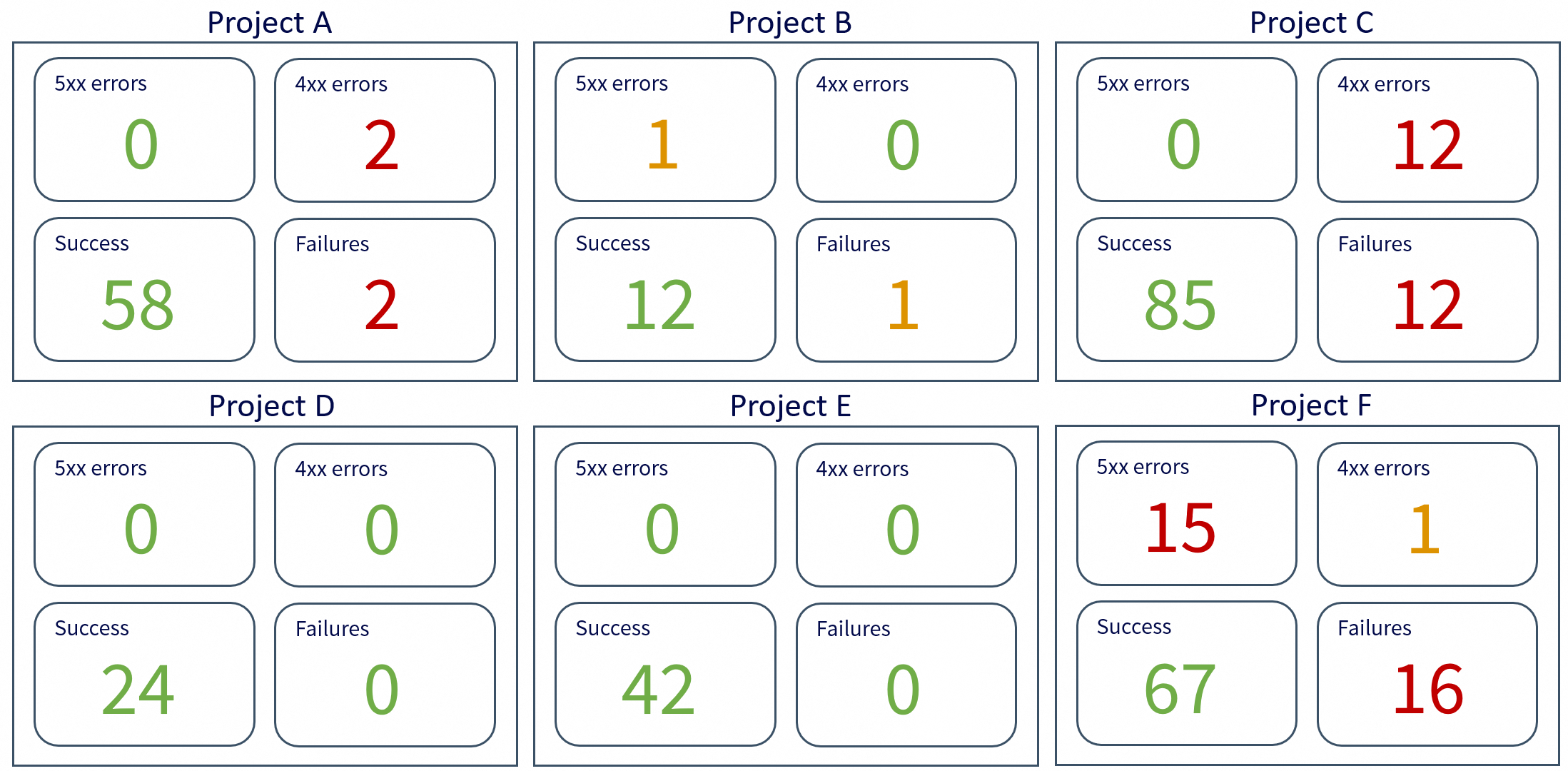
Le morning check consiste à consulter un dashboard central de tous nos services.
Ce dashboard est conçu pour ne pas être une agrégation imbuvable de tous les dashboards de l’équipe, mais se veut être un condensé des données les plus importantes.
Il faut y voir des métriques et des couleurs très claires :
- Vert : tout va bien.
- Orange : à surveiller.
- Rouge : quelque chose ne va pas, une action est à prendre.
En un coup d’œil et quelques scrolls, je dois être capable d’avoir connaissance de l’état global de tout notre périmètre.
Cela permet à la fois de vérifier qu’aucun problème majeur ne s’est produit pendant la nuit et d’anticiper les incidents potentiels de la journée à venir.
Les incidents
La qualité de prise en charge d’un incident est qualifiée par deux métriques :
- TTA : Time To Acknowledge, le temps que j’ai mis à informer que j’ai pris connaissance de l’incident.
- TRS : Time to Restore Service, le temps que j’ai mis à résoudre l’incident et à restaurer la situation à la normale.
Lorsqu’un incident tombe, la priorité est de l’acknowledger, puis deux actions :
- Affecter le projet correspondant (d’où l’utilité d’avoir des messages de log clairs).
- Requalifier la priorité si besoin.
Oui, parce qu’il existe plusieurs niveaux de priorité pour les incidents, selon la gravité et l’urgence.
Elles sont généralement classées de P1 (urgence maximale) à P5 (urgence minimale).
Selon les équipes, une P1 devra être résolue en un temps très court (généralement entre 2 et 4 heures), tandis que pour une P5, on peut avoir une bonne semaine, voire plus.
Les P1 sont les incidents qui peuvent sonner la nuit ou le week-end.
Évidemment, pour une P1 qui survient en journée (pendant le RUN donc), je ne suis pas seul : cela devient la priorité de toute l’équipe.
Surveiller les tickets
Les incidents en cours sont sous forme de tickets qu’on retrouve généralement dans un dashboard dédié.
Cela peut ressembler à ça :
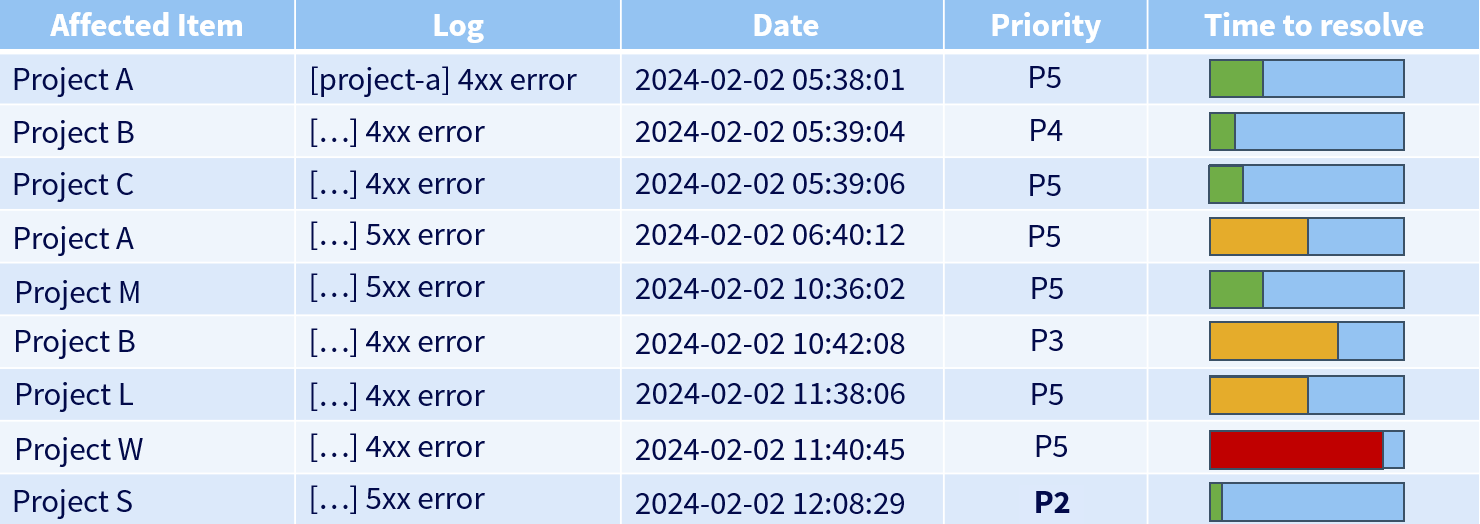
Ici, je peux voir que le projet W, de par son temps de résolution restant, était la priorité, jusqu’à ce que le projet S arrive avec une priorité bien plus élevée.
Le responsable du RUN doit toujours garder un œil sur l’ensemble des tickets, qu’ils lui soient affectés ou non, afin d’éviter de laisser passer le temps de résolution au-delà du temps maximal accordé.
Dans ce cas, on parle alors de breach : un dépassement du délai (ou plus généralement non-respect du SLA).
Être le point de contact
Une équipe est rarement indépendante, elle partage souvent son écosystème avec d’autres équipes. Lorsque vous devez remonter un problème urgent à une équipe concernant une demande particulière ou un bug que vous auriez pu trouver, vous communiquerez avec l’équipe concernée dans l’espoir d’obtenir une réponse rapide.
Quel que soit le support de communication de votre équipe (Slack, Webex, mails…), si vous posez une question dans un canal dédié à une équipe, celle-ci se doit d’être un minimum réactive.
Cette réactivité est alors assurée par le fait qu’un membre de cette équipe fait de la surveillance des canaux la concernant sa priorité afin d’apporter rapidement une réponse et de relayer si besoin.
Troubleshooting
Ceci étant dit, rentrons maintenant au cœur du sujet de la gestion d’incident : le troubleshooting.
Définition d’Oracle : Le troubleshooting (ou dépannage) est un processus de recherche logique et systématique de résolution de problème. Le troubleshooting consiste en une recherche de la source d’un problème afin d’en identifier les symptômes et d’en éliminer les causes potentielles, jusqu’à sa résolution.
Le troubleshooting, c’est comme mener une enquête : il s’agit de comprendre ce qu’il s’est passé avec les informations qui sont à notre disposition, afin de rétablir le service.
Il existe pas mal de méthodes pour faire du troubleshooting, j’aimerais m’axer sur celles que j’utilise principalement, à commencer par le Drill-Down.
La méthode de troubleshooting dite “Drill-Down” consiste à partir d’une vision large d’un problème (les symptômes visibles, le périmètre global impacté) puis à descendre progressivement vers des couches de plus en plus fines pour en identifier la cause précise.
On commence par vérifier les éléments les plus généraux : disponibilité du service, état global de l’infrastructure, métriques clés, etc.
Puis on “creuse” : composant par composant, couche par couche (réseau -> serveur -> application -> configuration -> code), jusqu’à isoler l’élément fautif.
C’est une approche structurée et rigoureuse. Elle a le défaut de ne pas être la plus rapide, surtout si on creuse dans la mauvaise direction, mais c’est selon moi l’une des meilleures méthodes pour établir ce qu’on appelle la Root Cause Analysis (RCA) : identifier les causes profondes des défauts ou des problèmes.
Aussi, cette méthode a l’immense qualité d’être un excellent moyen de monter en compétences sur un projet dont on peut avoir des connaissances limitées.
La rigueur de cette méthode de troubleshooting peut faire penser à la méthode “Bottom-Up”, qui consiste à commencer par examiner les composants physiques d’un système (couche inférieure) et à remonter progressivement les couches du modèle OSI jusqu’à identifier la cause du problème. Cette approche est efficace lorsque l’on soupçonne que le problème réside dans les couches basses du réseau.
En appliquant cette méthode dans un domaine purement logiciel, on commence par vérifier l’environnement d’exécution : s’assurer que l’application tourne bien, que les processus sont actifs et que le déploiement est correct. Ensuite, on contrôle les dépendances système, comme la base de données et les services associés, ainsi que la version des langages utilisés.
On teste ensuite la connectivité : le serveur web redirige-t-il bien les requêtes ? L’application accède-t-elle aux ressources nécessaires ?
Puis, on analyse les configurations et les logs pour identifier d’éventuelles erreurs.
Si tout semble en ordre, on examine le code source pour repérer des bugs récents ou des modifications problématiques.
Enfin, on teste l’interface utilisateur en inspectant la console du navigateur et les requêtes réseau pour voir si le problème vient du frontend ou du backend.
Je ne prétends pas être exhaustif ici, mais cela donne une idée de l’approche à avoir quand on mène l’enquête.
J’aimerais cependant mettre l’accent sur un point : si effectuer une root cause analysis est essentiel, ce n’est pas forcément la priorité.
Lorsqu’un incident survient, surtout lorsqu’il est critique, une question est primordiale à se poser :
“Ça ne marche pas” => Qu’est-ce qui ne fonctionne pas ? Tout ? Un scope en particulier ?
Est-ce qu’on est capable de reproduire l’erreur systématiquement ?
Bien que depuis tout à l’heure je parle de troubleshooting au sens “résoudre une enquête”, il ne faut jamais perdre de vue l’objectif initial : rétablir le service, et le plus vite possible.
Lorsque votre client perd l’accès à son site web hébergé chez vous, on peut facilement tomber dans le piège de vouloir immédiatement faire la RCA (root cause analysi). Il y a un problème, et on veut comprendre pourquoi.
Il faut parfois accepter le fait que comprendre la cause d’un problème puisse prendre du temps, et prioriser avant tout la disponibilité du service.
Cas pratique 1 : incident de nuit
J’aimerais commencer par un cas pratique d’une situation d’urgence. Écartons-nous du RUN deux minutes pour parler d’un incident d’astreinte de nuit.
Votre client a un problème avec son site web, il est subitement devenu très lent et une grande partie des requêtes entrantes sont perdues.
Il est 4h du matin.
Vous investiguez, vous voyez qu’il s’agit d’un site web load balancé sur 3 machines virtuelles.
Mon premier réflexe est alors d’évaluer l’impact de l’incident en regardant les différents dashboards de monitoring concernés, puis de regarder les logs associés au problème.
Mon réflexe suivant est alors de me connecter en SSH sur chacune de ces machines pour voir ce qu’il se passe. Sur l’une d’entre elles, rien à signaler.
Sur les deux autres, cela ne répond quasiment pas. Les connexions SSH prennent beaucoup de temps, la moindre commande à distance prend une trentaine de secondes à s’exécuter. Vous arrivez alors péniblement à afficher les ressources, qui avoisinent les 100% CPU / 100% RAM.
Premier bilan : deux machines sur trois ne sont plus en mesure de fournir le service demandé.
Le site web a un trafic énorme, c’est une grosse priorité, vous n’avez pas une minute à perdre. Demander au client d’attendre tout un troubleshooting avant de rétablir son service est inenvisageable.
Il faut gagner du temps.
Hors de question de redémarrer les machines qui ne répondent plus à la hâte, une investigation s’impose.
Mon premier réflexe fut alors de me diriger vers le load balancer afin de rediriger toutes les requêtes entrantes vers la seule machine qui tient encore debout.
Le load balancing n’ayant pas été mis en place sans raison, cette solution n’est évidemment pas viable sur le long terme, mais au moins le service est rétabli.
Il convient tout de même de s’assurer que le seul serveur fonctionnel sera capable de tenir la charge pour les heures à venir. Une surveillance accrue (hypercare) d’une bonne heure s’impose avant de partir se recoucher.
Le service tient sur une jambe, mais il tiendra la nuit le temps que mes collègues se réveillent.
Le lendemain, nous avons pu faire tout le troubleshooting nécessaire en équipe afin de corriger le problème durablement et répartir à nouveau la charge sur les 3 machines.
Cas pratique 2 : prise de recul
Passons sur un cas un peu moins urgent, typique du RUN. Il y a tant d’exemples de troubleshooting que je ne sais lequel choisir.
J’ai choisi le cas que je vais vous présenter pour deux raisons : c’est l’un des premiers cas que j’ai eus au sein de mon travail actuel, et c’est le premier où j’ai réalisé l’importance de sortir de mon cadre de pensée.
Ce que je veux dire par là, c’est que comme je l’ai dit plus haut, lorsqu’un incident se présente, on va tout de suite se forger une intuition en se basant sur le peu d’informations que l’on a à première vue, pour ensuite creuser. Mais le troubleshooting ne se résume bien souvent pas à ça. La plupart du temps, il y a tout un contexte à prendre en compte : les contraintes métiers, les services qui gravitent autour de celui qui est concerné, l’infrastructure sur laquelle il tourne…
Je vais légèrement modifier l’exemple par souci de confidentialité, mais le principe reste le même.
Reprenons notre microservice de synchronisation d’utilisateurs d’un point A à un point B :
[user-sync-service] creating user: POST /api/users: 500....
Il s’agit ici d’une erreur 500. Le microservice n’a pas réussi à pousser les utilisateurs vers la destination. Des pushs qui ratent, donc.
Premier réflexe, je regarde le dashboard des métriques pour évaluer l’ampleur des dégâts. Je vois qu’il y a environ 20% de requêtes en erreur 500 pour 80% de requêtes en 200 sur la même route.
Déjà, on peut se dire que tout n’est pas par terre.
Je remarque également qu’il s’agit d’une synchronisation qui envoie beaucoup de requêtes en peu de temps.
J’ai alors pensé à un problème dû à un rate limiting ou une surcharge de requêtes, mais en regardant l’historique des autres synchronisations je vois que l’on est sur une volumétrie similaire à celle que nous avons toujours eue.
Ensuite, regardons les logs.
Note : Un message de log bien fait, d’erreur ou pas, ne contiendra qu’un message très simple concernant ce qu’on essayait de faire.
Toutes les autres informations se trouveront dans les champs du log, que nous pouvons utiliser pour filtrer.
Je commence donc par filtrer tous les messages de log qui contiennent une erreur, afin de leur trouver un point commun. Sachant que nous mettons toujours un champ “operation” qui est une sorte de code sur l’opération faite au moment de l’envoi du message, je décide de l’afficher pour voir.
| message | operation |
|---|---|
| error: creating user | createUser |
| error: creating user | createUser |
| error: creating user | createUser |
La première chose que j’observe est que l’intégralité des erreurs porte le même message et la même opération.
Il semble donc y avoir un problème avec la création des utilisateurs, c’est ce que les messages semblent indiquer.
Je pourrais alors creuser vers le processus de création d’utilisateurs pour voir ce qui ne va pas, mais je me rappelle qu’une bonne partie des requêtes étaient en 200, et me dis que ce n’est certainement pas suffisant de ne filtrer que sur les erreurs.
Je retire donc ce filtre et affiche l’intégralité des messages autour des messages d’erreur :
| message | operation |
|---|---|
| error: creating user | createUser |
| success: creating user | createUser |
| error: creating user | createUser |
| success: creating user | createUser |
| success: creating user | createUser |
| error: creating user | createUser |
Il y a en réalité plein d’opérations createUser qui se passent bien. Le problème ne vient peut-être pas de l’opération elle-même.
Je me balade dans les champs disponibles et l’un d’eux attire mon attention : le pod_id, l’ID du pod sur lequel tourne le microservice côté infra.
Je décide de l’afficher :
| message | operation | pod_id |
|---|---|---|
| error: creating user | createUser | app-54fb9-n4vkg |
| success: creating user | createUser | app-54fb9-n4vkg |
| error: creating user | createUser | app-54fb9-n4vkg |
| success: creating user | createUser | app-54fb9-n4vkg |
| success: creating user | createUser | app-54fb9-n4vkg |
| error: creating user | createUser | app-54fb9-n4vkg |
Et là, un truc me frappe : après vérification, l’intégralité des messages, success comme error, viennent du même pod.
Pourtant, j’ai un minimum de connaissance sur ce microservice et je sais qu’il est supposé tourner sur deux pods, notamment pour répartir la charge. C’est suspect.
Donc plutôt que de me diriger vers le code source, je me connecte à l’infra pour surveiller l’état des pods, et bingo : l’un des deux était tombé.
La charge s’est alors retrouvée concentrée sur un seul pod, qui s’est alors retrouvé en difficulté pour tout gérer, et qui a drop une partie des requêtes.
C’était donc bien de la surcharge de requêtes après tout.
J’ai relancé le pod, relancé la synchronisation, la charge s’est de nouveau répartie sur les deux pods, tout est passé.
Il ne reste plus qu’à creuser pourquoi ce pod est tombé, mais une grosse partie de la RCA est établie.
Nous pouvons clore l’incident.
Cet exemple montre qu’avoir une vue d’ensemble sur les informations que nous avons à notre disposition peut nous permettre d’élargir notre intuition vers une cause qui n’était pas forcément soupçonnée au premier abord.
Les Five Whys
J’aimerais terminer de parler de troubleshooting en évoquant une autre méthode nommée les “Five Whys”.
Définition Wikipédia : Les cinq pourquoi (ou 5 Whys) sont une technique d’interrogation itérative permettant d’explorer les relations de cause à effet sous-jacentes à un problème particulier.
L’objectif principal de cette technique est de déterminer la cause profonde d’un défaut ou d’un problème en répétant cinq fois la question « pourquoi ? », en reliant à chaque fois le « pourquoi » actuel à la réponse du « pourquoi » précédent.
La méthode affirme que la réponse au cinquième « pourquoi » posé de cette manière devrait révéler la cause profonde du problème.
Exemple :
Problème : Je suis en retard au travail.
Pourquoi ? Je suis parti de chez moi plus tard que d’habitude.
Pourquoi ? Mon réveil n’a pas sonné.
Pourquoi ? Mon téléphone était éteint.
Pourquoi ? La batterie était vide.
Pourquoi ? Je n’ai pas branché mon téléphone avant de dormir.
La cause de mon retard au travail serait donc le fait d’avoir oublié de charger mon téléphone, et une solution pour que cela ne se reproduise plus serait que j’y fasse plus attention à l’avenir.
Cet exemple est très classique et est plutôt pratique pour illustrer les avantages et inconvénients de cette méthode.
- Avantage : Cela pousse à prendre du recul sur ces incidents qui se produisent.
- Inconvénient : Cela sur-simplifie un peu trop les problèmes. Penser à charger mon téléphone ne me garantit en rien d’être à l’heure au travail les prochains jours.
Prenons un autre exemple technique :
Problème : Les utilisateurs ne peuvent plus se connecter à l’application.
Pourquoi ? Le système d’authentification renvoie une erreur 500.
Pourquoi ? Le service d’authentification est incapable d’interroger la base de données des utilisateurs.
Pourquoi ? Le service d’authentification ne peut pas établir de connexion avec la base de données.
Pourquoi ? Le serveur de base de données est inaccessible.
Pourquoi ? Une modification récente de la configuration du pare-feu a empêché le service d’authentification d’accéder à la base de données.
Cette méthode reste intéressante pour prendre du recul avant de foncer tête baissée sur la résolution d’un incident et est souvent utilisée lors de la rédaction de post-mortems afin d’avoir une autre vision du problème.
Le troubleshooting est un domaine assez vaste. Je ne prétends pas avoir été exhaustif mais j’espère avoir pu vous apporter quelques pistes de réflexion sur le domaine.
Être un développeur résilient
J’ai développé ici les principaux axes que je voulais aborder concernant le RUN.
Cependant, je me pose quand même une question :
Ce que je veux dire, c’est que si j’ai été capable aussi rapidement de prendre en main ces outils et d’accéder aux informations en cas d’incident, c’est parce que ces outils et ces informations existent.
Les logiciels et microservices sont écrits par des développeurs, et ces développeurs ont leur rôle à jouer dans le processus de troubleshooting bien en amont des incidents eux-mêmes.
Je veux vous parler des bonnes pratiques de dev qui sont nécessaires à une bonne gestion d’incidents, et j’ai pour cela rédigé un blog post Être un développeur résilient dédié à cette thématique.
Si je devais résumer une idée derrière cet article, ce serait la suivante :
“Développez vos applications comme si vous alliez les maintenir, parce que c’est le cas !”
N’hésitez pas à le lire si vous voulez en savoir plus sur le quotidien d’un développeur qui travaille dans un contexte d’incidents, sinon je vous laisse terminer cette lecture sur un petit mot de la fin !
Petit mot sur l’astreinte de nuit
C’est ici que se termine ce blog post sur la gestion d’incidents en RUN.
J’ai préféré me focaliser sur cet aspect de la gestion d’incidents car il représente plus mon quotidien que les astreintes de nuit, même si j’ai pu détailler un cas typique de nuit, mais c’est vraiment quelque chose qui peut varier selon les équipes.
J’ai envie de vous laisser sur un petit blog post que j’ai beaucoup aimé sur des choses qui sont selon moi utiles à avoir en tête lorsque l’on est d’astreinte de nuit : What I tell people new to on-call
J’espère que ces quelques lignes (ou plutôt quelques pages) vous auront appris des choses et vous auront donné une idée du quotidien des ingénieurs qui côtoient régulièrement les incidents.
Conclusion
Ce passage au RUN a radicalement changé ma vision du métier. Pendant douze ans, j’ai vécu dans le confort de l’abstraction, là où le travail d’un ingénieur logiciel s’arrête au développement de son code. Aujourd’hui, je sais que le code n’est qu’une étape et que la finalité, c’est que ça tourne.
Le RUN n’est pas une simple corvée ou une succession d’alertes. C’est le moment où l’on se confronte à la réalité. Cela demande de l’humilité : il faut accepter qu’on ne peut pas tout maîtriser sur une cinquantaine de services, mais qu’avec de la méthode, on finit toujours par s’en sortir.
Si j’avais un conseil à donner à ceux qui, comme moi, ont toujours eu peur de la prod : n’ayez pas d’appréhension. Elle ne cherche pas à vous piéger, elle vous apprend à mieux coder. En assumant la responsabilité de ce que l’on construit, on ne devient pas seulement des développeurs plus complets, on devient des ingénieurs plus résilients.
Sources
- https://www.ibm.com/think/topics/it-operations
- https://preslav.me/2023/04/14/golang-error-handling-is-a-form-of-storytelling/
- https://www.maddyness.com/2019/12/23/startupers-build-et-run/
- https://www.oracle.com/fr/security/troubleshooting-depannage-resolution-problemes/
- https://ntietz.com/blog/what-i-tell-people-new-to-oncall/
- https://en.wikipedia.org/wiki/Five_whys
- https://medium.com/@dzanna.molly/devops-troubleshooting-strategy-2b5b38a5f3b7
- Monitoring efficace : comment sauver votre production rapidement - Antoine Beyet (https://www.youtube.com/watch?v=6pRBWM-J-c8)