
Le défi
Aujourd’hui, j’aimerais vous raconter mon tout premier défi CTF, lors du Hackathon OVHcloud 2024 (événement interne).
De tous les défis de ce Hackathon auxquels j’ai participé, c’est celui qui m’a le plus marqué. Je l’ai trouvé à la fois intéressant et amusant. J’ai particulièrement apprécié sa simplicité : le problème se comprend très vite, mais nécessite plusieurs étapes pour être résolu.
Il se présente sous la forme de cette simple page web :
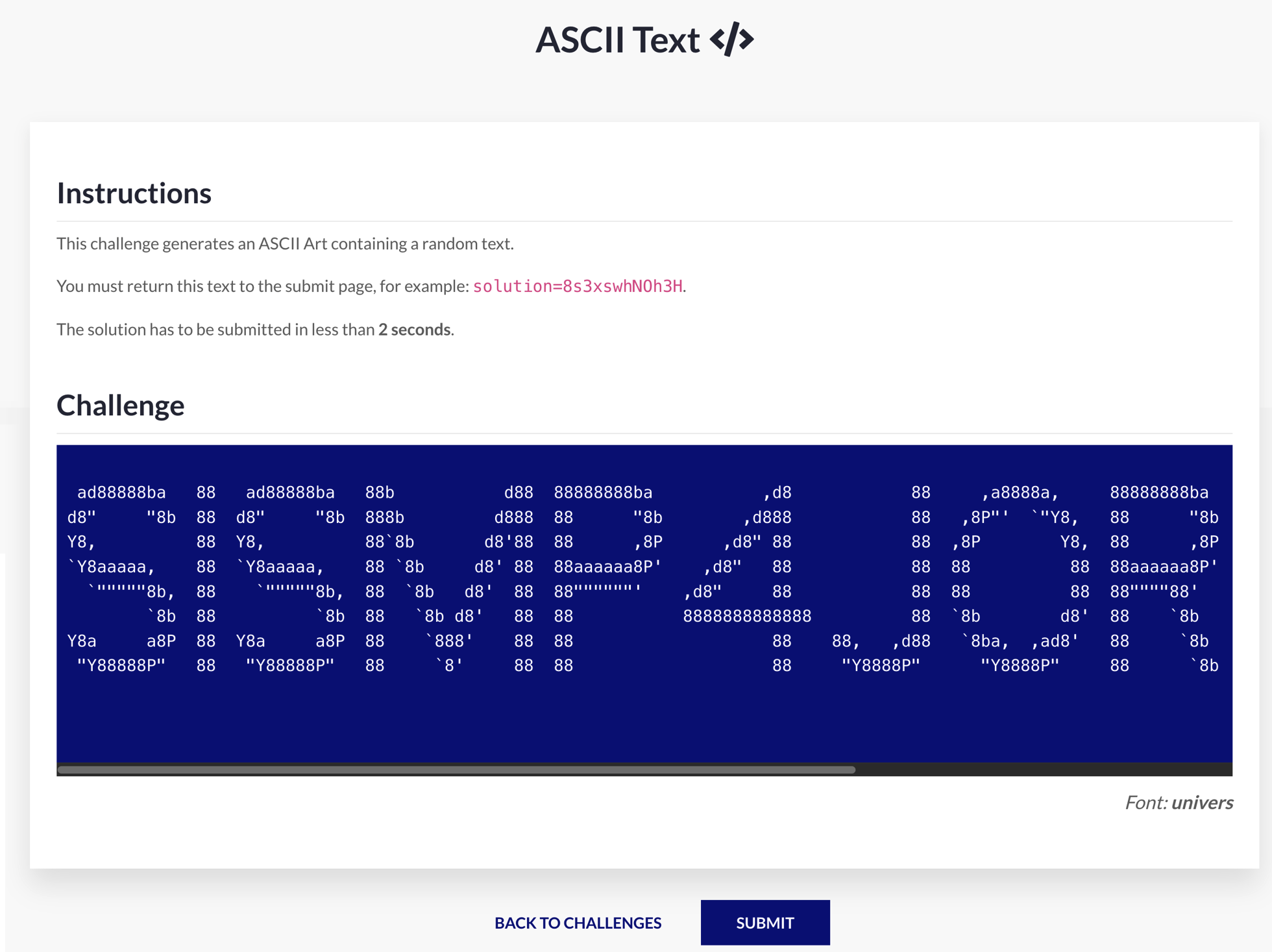
OK, tout est écrit. Il y a un code qui apparaît en ASCII art. Je dois renvoyer ce code via l’URL de soumission en moins de 2 secondes. Totalement impossible pour un humain, je vais donc devoir automatiser le processus.
Prise d’informations
La toute première étape, c’est d’éliminer les inconnues et d’obtenir le maximum d’informations. En rafraîchissant la page quelques fois et en inspectant le code HTML, j’obtiens mes réponses.
Combien de caractères ?
Il y en a toujours 12.
La police est-elle toujours la même ?
Non. Il y a plein de polices différentes à chaque fois. Ça rajoute une difficulté supplémentaire.
Le code correspondant est-il présent quelque part dans le code HTML de la page web ?
Bien sûr que non, mais ça valait le coup de vérifier.
Les étapes
Ceci étant dit, il est temps d’automatiser le processus. Posons-nous une question : il existe des tonnes d’outils dans le monde du logiciel capables de générer de l’ASCII art à partir de caractères, mais est-ce que l’inverse existe ?
Pour être honnête, je n’ai pas beaucoup d’espoir. L’utilité d’un tel système étant très limitée, je doute que beaucoup de gens se soient amusés à programmer ce genre de chose, sauf pour un défi.
Mais pour être encore plus honnête, je n’avais même pas vraiment envie de chercher, car j’avais une idée plus intéressante en tête.
Avez-vous déjà entendu parler des OCR ? Ça signifie Optical Character Recognition (reconnaissance optique de caractères). Ce sont des outils basés sur le deep learning qui se spécialisent dans la reconnaissance de caractères, de mots ou de phrases dans des contextes visuels.
On les retrouve dans des outils qui nous entourent au quotidien : reconnaissance des codes postaux sur les enveloppes, génération de documents PDF à partir d’une photo de texte, automatisation de la vérification de documents d’identité, lecture de photos de radars, ou encore aides pour les personnes malvoyantes.
C’est exactement ce dont on a besoin, non ? Oui, mais il va falloir passer par plusieurs étapes.
D’abord, l’ASCII art sur la page web n’est pas une image mais un ensemble de caractères affichés.
Ensuite, on ne s’intéresse pas à toute la page web, juste à la partie contenant l’ASCII art.
Enfin, l’idée serait de prendre une capture de cette partie de la page web et de l’envoyer à l’OCR.
Sans avoir de connaissance particulière en OCR, et même si j’ai un minimum de confiance en son fonctionnement, s’il y a bien une chose que j’ai toujours retenue en IA, c’est que le prétraitement des données est aussi important, si ce n’est plus, que le traitement par deep learning en lui-même.
La donnée ici, c’est une image, on va donc devoir faire un minimum de traitement d’image.
Si je ne me trompe pas, mon plan est parfait : il ne reste plus qu’à envoyer la sortie de l’OCR dans la requête de soumission.
Voici donc le plan :
- Récupérer la page web via une requête HTTP GET
- Faire du web scraping sur la page web afin d’extraire uniquement la partie qui nous intéresse (l’ASCII art)
- Générer une image à partir de l’ASCII art
- Faire du traitement d’image afin de la rendre plus facilement lisible pour un OCR. Ici, je vais juste mettre le dessin en noir sur blanc, en jouant sur les contrastes pour le rendre plus net
- Donner l’image à l’OCR
- Récupérer le résultat pour le coller dans la requête de soumission
- Il ne reste plus qu’à lire le résultat
C’est parti
Web scraping
Je choisis d’utiliser le langage Python, le plus adapté et le plus simple pour ce qu’on veut faire.
Grâce à la librairie Requests, je récupère le contenu complet de la page web.
|
|
Ensuite, je parse le contenu avec BeautifulSoup.
Il n’y a qu’une seule balise <pre> dans le code HTML. Cette balise représente du texte préformaté qui doit être présenté exactement tel qu’il est écrit dans le fichier HTML. C’est elle qui contient les données qui nous intéressent.
|
|
Après quelques essais, voici ce qui s’affiche dans mon terminal :
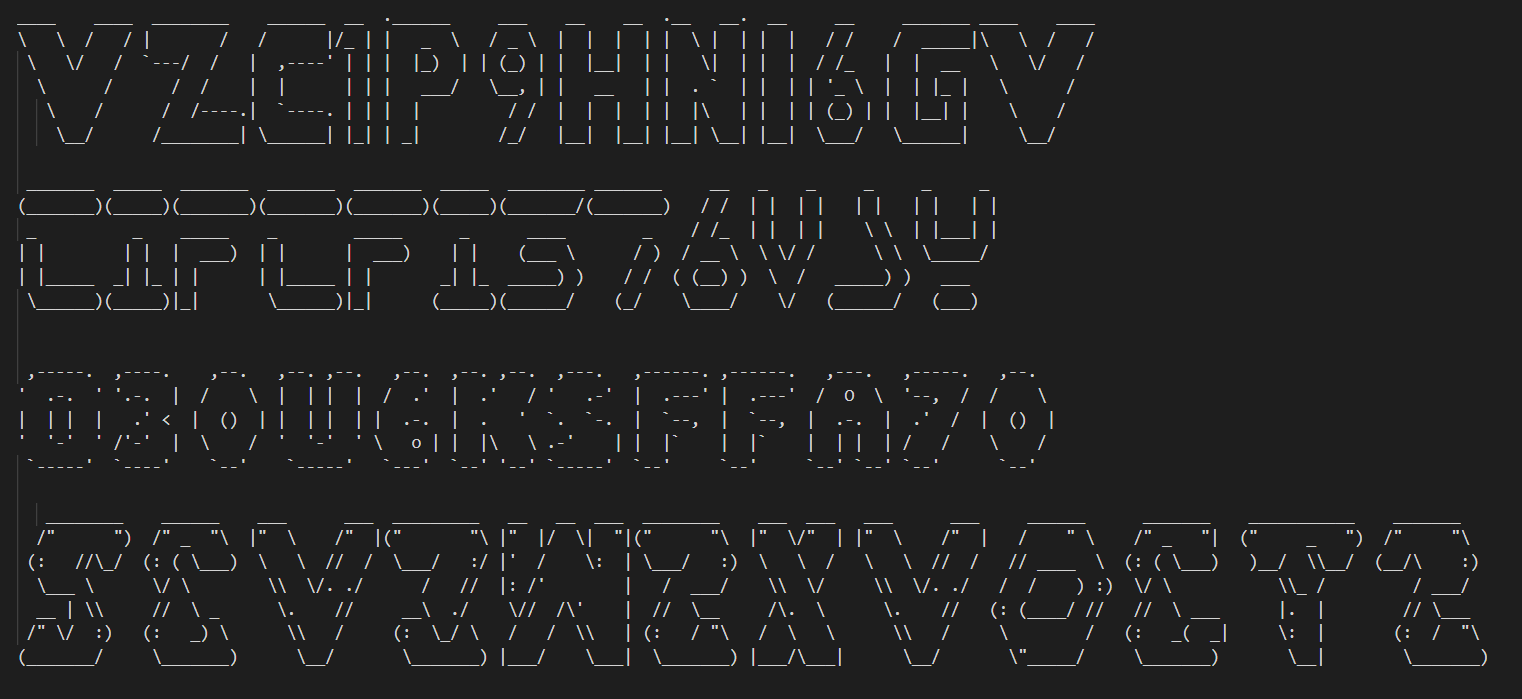
Traitement d’image
Passons maintenant au traitement d’image.
J’ai d’abord pensé à OpenCV. Mais comme l’installation sur mon laptop prenait une éternité, j’ai trouvé une autre librairie de traitement d’image que je ne connaissais pas : Pillow. D’après ce que j’ai lu, elle est certes plus limitée en fonctionnalités mais beaucoup plus légère, et plus rapide pour des traitements simples. Exactement ce qu’il me faut, essayons !
D’abord, je crée l’image à partir de la sortie :
|
|
Ensuite, je définis une fonction de prétraitement :
|
|
Il ne reste plus qu’à appeler ma fonction de prétraitement :
|
|
Voici quelques résultats :


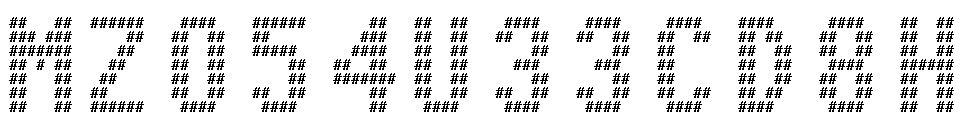
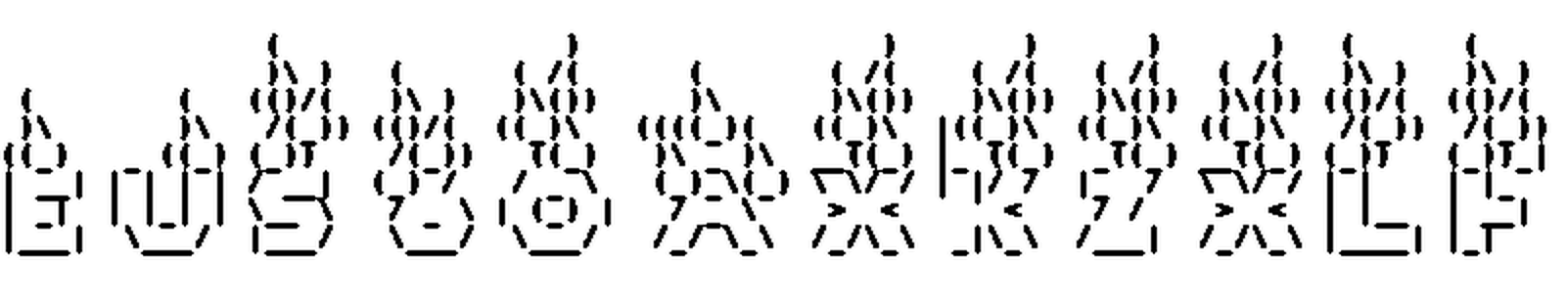
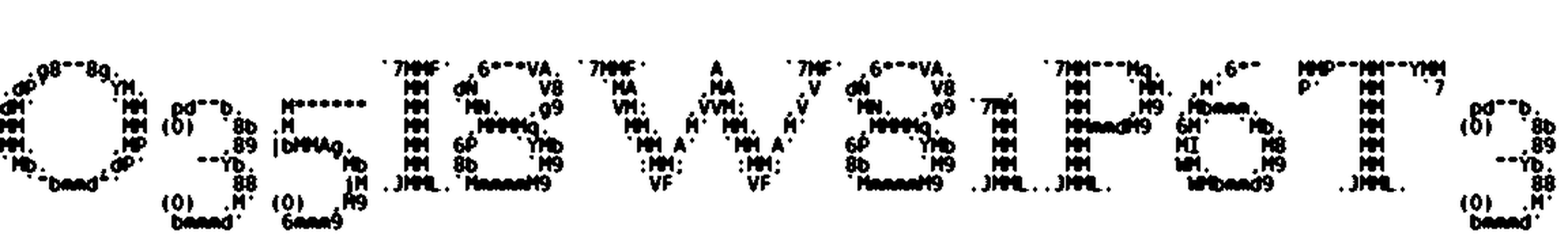
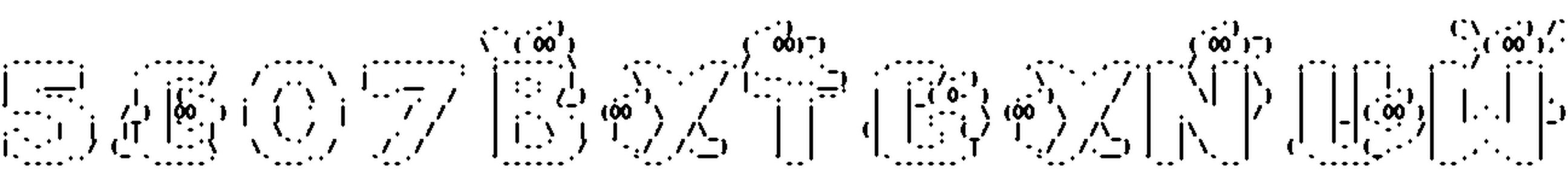
Pas mal du tout ! Toutes les étapes préliminaires sont faites, place maintenant à la pièce maîtresse de notre solution : l’OCR.
Reconnaissance optique de caractères (OCR)
Si j’ai immédiatement pensé à un OCR en attaquant ce défi, c’est parce que j’en connaissais déjà un avec lequel j’avais un peu joué il y a plusieurs années : Tesseract OCR.
Cet OCR, développé par Google, a un taux de réussite très élevé, mon choix était déjà fait.
Il se trouve qu’il existe un wrapper Python de cette librairie : pytesseract.
Cette librairie est très simple d’utilisation et clé en main. On lui donne une image contenant du texte, elle nous renvoie le texte. Facile.
Écrivons ça :
|
|
Voyons les résultats !
L’image :
Le résultat :
|
|
Aïe. On dirait que quelque chose ne va pas.
Vous savez, je suis juste développeur. Parfois je ne lis pas toute la documentation.
Si je l’avais fait, j’aurais su une chose importante à propos de Tesseract OCR : il y a 13 modes de fonctionnement, et le mode par défaut n’est pas du tout celui dont j’avais besoin.
Le mode par défaut est le PSM 3 : Fully Automatic Page Segmentation, But No OSD. (OSD signifie “Orientation and Script Detection”. C’est une fonctionnalité de Tesseract qui détecte automatiquement l’orientation du texte dans une image et tente d’identifier le script utilisé)
Dans ce mode, Tesseract va automatiquement segmenter la page et essayer de reconnaître le texte.
Voici quelques modes utiles à connaître :
-
PSM 5 : Assume a single uniform block of vertically aligned text
Tesseract considère que l’image en entrée contient un seul bloc de texte, comme un paragraphe ou une page avec une taille de police et une structure uniformes. -
PSM 6 : Assume a single uniform block of text
Similaire au PSM 5, mais ce mode considère que le bloc de texte est plus susceptible d’être aligné horizontalement. Souvent utile pour les images simples contenant un seul bloc de texte. -
PSM 7 : Treat the image as a single text line
Tesseract considère que l’image en entrée ne contient qu’une seule ligne de texte, ce qui peut améliorer la précision avec des entrées plus petites. -
PSM 8 : Treat the image as a single word
Tesseract considère que l’image en entrée ne contient qu’un seul mot. Ce mode est utile pour reconnaître des mots isolés.
Vous avez deviné quel mode va nous intéresser ici ?
Le mode PSM 8 bien sûr !
Ce mode se configure via l’option --psm 8
J’ai également compris autre chose sur le fonctionnement par défaut de Tesseract : il va chercher la correspondance entre les mots qu’il lit et ceux d’un dictionnaire, en anglais par défaut.
Ici, ça ne nous intéresse pas et on ne veut pas que Tesseract soit influencé par un quelconque dictionnaire, mais qu’il interprète ce qu’il lit caractère par caractère.
Ça se configure via l’option -c
Mieux encore, Tesseract offre la possibilité de limiter le domaine de reconnaissance de caractères à une liste blanche. Je lui donne donc les caractères a-z, A-Z et 0-9.
Voici donc le code pour appeler pytesseract, avec la bonne configuration :
|
|
Testons ça :
L’image :
Le résultat :
|
|
On tient enfin notre résultat !
Capture the flag
J’aurais aimé vous dire que j’ai mesuré le temps exact de toute l’opération, mais j’avoue que dans le feu de l’action je n’y ai pas du tout pensé. Je n’ai clairement pas choisi les technologies les plus rapides d’ailleurs, mais ce que je peux vous dire, c’est que ça a pris moins de deux secondes.
La durée du processus étant respectée, je n’ai plus qu’à ajouter le résultat dans la requête de soumission. J’ajoute au cas où une condition qui invalide le résultat de Tesseract si le mot trouvé ne fait pas exactement 12 caractères, et c’est parti !
|
|
Réponse :
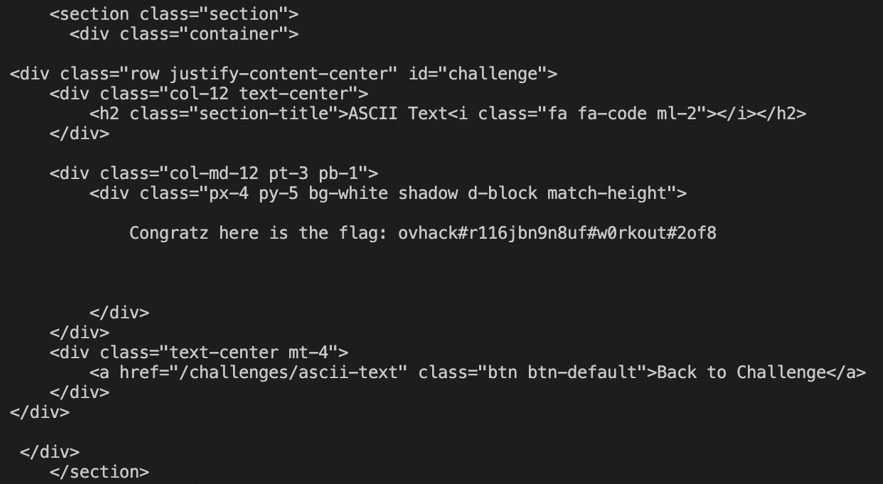
Flag capturé, en route vers le prochain !
Encore un très grand merci à OVHcloud et à tous les organisateurs de ce Hackathon, qui ont fait passer un super moment à mes collègues et moi-même ♥